- previous: The Memex Service API
- next:
Continuing the series of posts about building a digital brain, I bring to you today the MVP of the management system for my personal data. The intention is to be able to store the data in a single place owned by me and to be able to query in any way I want without API limitations, premium plans, etc.
Why is this important? Well, while other countries are returning to normal, my country is on an all time high pandemy, therefore I’m in need of a major project to focus on. Second, there’s the perspective of knowing one’s data. Third, knowing oneself is the key to happiness and good decisions.
How am I tackling this? I wrote a small proposal of the general architecture in a previous post of this series. In summary, my system relies on three modules: exporters, importers, and a service API for fetching and filtering. I’m also working on a frontend app which I’m still not sure on how to classify.
What are my general goals? I want to build something for myself. I want this to be a learning project, expect to see me trying different things to solve the same issue, expect to see me discussing details of approaches that ended up being a dead end.
Where did this idea come from? Main source of inspiration was the work of Karlicross and Andrew Louis. I point to sources here.
Now that the introduction has been covered, let’s get to the point. My tech stack is Python, Flask, React, and MongoDB. I’m taking full advantage of document’s databases to insert data of various forms. My backend is a simple flask server with one route that handles queries. My frontend is a separate react app that deals with the rendering.
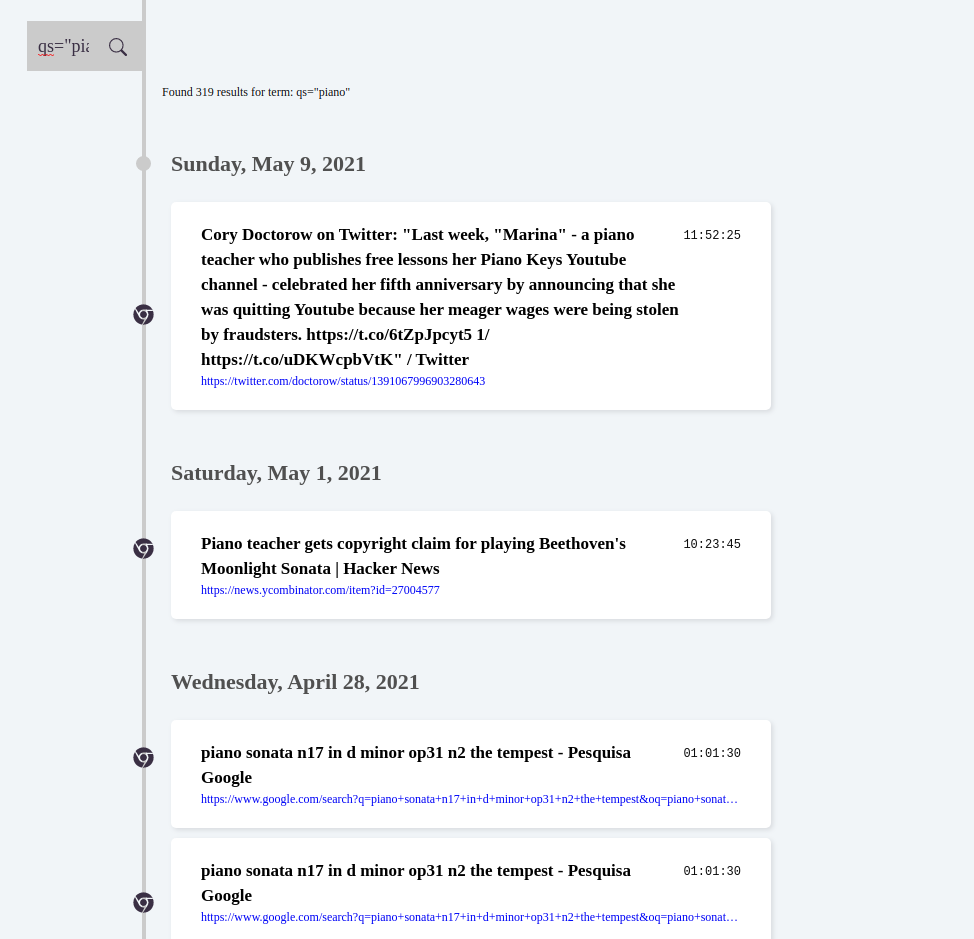
General features are:
- Text search. This is the main functionality of the app and I can say that the query pattern will be the one to go through most changes. I’m using the default text search provided by MongoDB. It works by creating a text index that includes any field which has as value a string or an array of string elements. The query language is still rudimental and requires further research.
- Infinite scroll. I’m taking advantage of the API to provide paginated results that are fetched sequentially by the frontend using react-query.
I started this project with four data types, but since then the number has increased:
- Mood (daylio app for android)
- Habits (habits app for android)
- Browser history (google chrome)
- CLI commands (terminal)
- Github notifications and events
- Stats of time spent on the web (rescuetime)
- Credit card and bank account history (nubank)
The Good
As you would expect, querying your own data is extremely useful, finding old and lost articles, music, and commands. MongoDB was extremely easy to setup and populate, right now I have around 70.000 entries on my database and it takes milliseconds to write everything to the database and milliseconds to perform any type of query.
The Bad
Data from different sources usually have different formats. Despite trying to create common ground between the different sources, much of the data has no equivalence outside of its own scope. All entries share a common set of attributes plus their actual metadata, in practice I can rely on the fact that entries will have a provider, activity, principal_entity, activity_entities, datetime, device_name, timezone and a timestamp_utc.
The bad thing here is that each log from a different provider has its own format. The consequence of this is that for each input type added to the project, one new component needs to be implemented on the frontend to show the details properly. Here’s a sample of how different the inputs are:
// daylio
{
"acitvity": "rated",
"acitvity_entities": ["day"],
"datetime": {"$date": 1610582700000},
"details": "",
"device_name": "Galaxy S10",
"mood": "good",
"principal_entity": "Rebeca Sarai",
"provider": "daylio",
"things_i_did": "reading | Writing | Piano | Coffee | Self ,Reflection | Running",
"timestamp_utc": "1610582700.0",
"timezone": "America/Recife",
}
// rescuetime
{
"acitvity": "tracked",
"acitvity_entities": ["site"],
"activity": "old.reddit.com",
"category": "General News & Opinion",
"datetime": {"$date": 1622429940000},
"device_name": "Web App",
"number_of_people": 1,
"principal_entity": "Rebeca Sarai",
"productivity": -2,
"provider": "rescuetime",
"time_spent_in_seconds": 300,
"timestamp_utc": "1622429940.0",
"timezone": "America/Recife",
}
// habits
{
"acitvity": "marked",
"acitvity_entities": ["run"],
"datetime": {"$date": 1617494400000},
"device_name": "Galaxy S10",
"principal_entity": "Rebeca Sarai",
"provider": "habits",
"timestamp_utc": "1617494400.0",
"timezone": "America/Recife",
}
The Ugly
The query language thus far is extremely rudimental. I rely on a special key to perform text-search around pre-defined fields and key-value pairs to search on the remaining ones (not seeing much use of this). Other than that, I’m still confused about how the query system works, eg:
- qs=”my tears ricochet” returns 9 results
- qs=my tears ricochet returns 9 results
- qs=my returns 0 results
- qs=My returns 0 results
- qs=tears returns 9 results
It makes me think if one should not use a ready-to-use tool with a complex and validated query language such as elastic search.
Next Steps
- Add support to different types of visualization
- Built-in graphs
- Autocomplete
However, before diving into the next features I would like to test different approaches here. Especially regarding database types, my next will be elastic search and neo4j.
- previous: The Memex Service API
- next: